接下来一段时间, 会将主要精力投入在SQL优化 以及工作中常用的一些SQL小技巧总结。当然啦, 也会对Hive、Spark SQL 和 Presto 中的SQL使用做一些总结。之前SQL写得比较少, 更多的是用的pyspark进行大数据处理, 后端服务更多的用Mybatis自动生成工具来生成DAO层SQL代码,然后在Service层进行多次调用, 一是因为业务逻辑不复杂, 二是因为性能要求也没那么高。不过, 总感觉SQL这块如果不掌握的话, 可能后面发展会受限。好了, 废话不多说, 我们开始一段时间的 SQL 之旅吧。
实验数据
表1. user: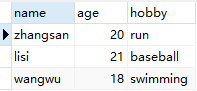
表2. job: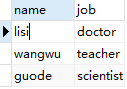
表3. sports_duration: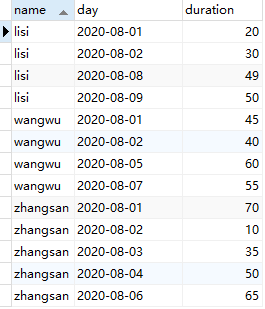
1. 如何在MySQL中使用full join?
场景: 将上面的user 表和 job表 合成一张大表。
full join 就是取两者的并集, 而MySQL中是不能使用full join 的, 下面来说下解决方法:
使用表user left join 表job, 然后 union all 表user right join 表job(其实也就是表job left join 表user)即可, union all 就是两者的并集。
sql 如下:
1 | select u.name, u.age, u.hobby, j.name as jname, j.job from user u left JOIN job j on u.`name` = j.name |
结果如下: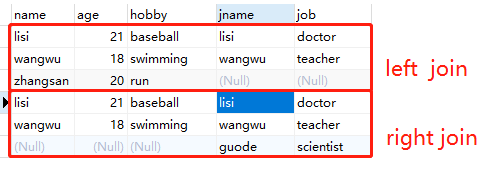
通过上图, 我们也可以很清楚的看到 left join 和 right join 后的效果。
user left join job 就是user 表作为主表, 将 job 表中与 user表有关联关系的数据作为补充, 详见 上图 left join 红框。
另外, 通过指定 where jname is null, 我们也可以取到 user 表中有而 job 表中不存在的用户。
right join 同理, 这里就不赘述了。
2. 如何更新使用过滤条件中包括自身的表?
场景: 把同时存在于 user表 和 job表的记录的用户在user 表中的age 字段更新为30。
错误示例:
1 | update user set age=30 where user.name in (select j.name from user u join job j on u.name=j.name); |
报错:
1 | update user set age=30 where user.name in (select j.name from user u join job j on u.name=j.name) |
说明: MySQL 中不支持这样操作, 在 SQLServer 或者 Oracle中可以正常执行。
正确解法:
1 | update user u join (select j.name from user u join job j on u.name=j.name) j on a.name=j.name set u.age=30; |
更新结果如下: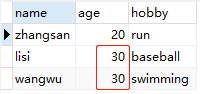
3. 如何使用 join 来优化子查询?
先看下面这个带有子查询的sql:
1 | select u.name, u.age, u.hobby, (select job from job where job.name = u.name ) as job from user u; |
使用 join 优化:
1 | select u.name, u.age, u.hobby, job from user u left join job j on u.`name` = j.`name`; |
4. 使用join来优化聚合子查询
场景: 找出user 表中三人, 各自运动时长最长的日期。新增表 sports_duration, duration 为运动时长, 单位: 分钟
聚合子查询:
1 | select u.name, s.day, s.duration from user u |
结果如下: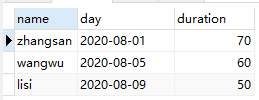
使用join优化后, 避免子查询:
1 | select u.name, s.day, s.duration from user u |
返回的结果集是相同的。
5. 如何实现分组选择?
在 Oracle、SQLServer、PgSQL中可以使用分区查询函数实现:
1 | with tmp as ( |
但是, 在 MySQL中不支持。
我们可以这样做:
1 | select u.name, d.day, d.duration from ( |
结果如下: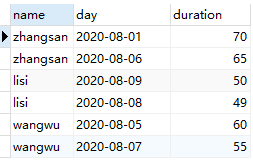
下面我们来拆分这个SQL:
1 | select u.name, d.day, d.duration, cnt from ( |
去掉 where条件, 加上返回 cnt 字段, 就可以很清晰的看到明白这个sql的逻辑了, 结果如下图: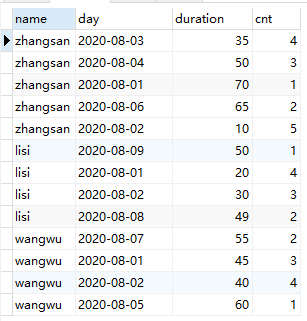
利用子查询中统计出用户运动耗时大于等于当前运动记录的条数, 然后再进行过滤。